Custom Reporting via the Preservica Content API

James Carr
November 29th, 2021
Preservica provides a REST API to allow users to query the underlying search engine. In this article we will show how CSV documents can be returned by the API.
Preservica provides a REST API to allow users to query the underlying search engine. The Search engine provides access to all the indexed information within a Preservica system, this includes the standard metadata attributes such a title, description etc. and also any organization specific custom indexes added by users.
This API is available for all on-premise and Cloud Professional Edition customers and above.
This REST API is documented at https://eu.preservica.com/api/content/documentation.html
In this article we will show how CSV documents can be returned by the API, CSV is a convenient format because it can be opened directly within spreadsheet software such as LibreOffice or MS Excel. Once inside a spreadsheet post processing such as filtering, sorting and charting can easily be applied to the data to create custom reports.
Search Indexes
Before using the search API, it’s a good idea to familiarize yourself with the available indexes held by the search engine. This will give you an idea of what information can be returned by the search queries and therefore what can be reported on.
You can determine the available indexed fields within a Preservica repository by calling the
/api/content/indexed-fields
endpoint.
You can call the API using any REST client such as Postman, but for following examples we will use the 3rd party python library pyPreservica.
pyPreservica is an easy to install Python client which takes care of the authentication, xml parsing and error handling automatically.
Using pyPreservica the list of fields is available using:
from pyPreservica import *
search = ContentAPI()
for index in search.indexed_fields():
print(index)
This will print all the available indexes, The default indexes available in every system start with the xip prefix, but the list will also contain any custom indexes created when using a custom search index rules document.
e.g.
…
xip.format_r_Display
xip.format_r_Preservation
xip.full_text
xip.identifier
xip.is_valid_r_Display
xip.is_valid_r_Preservation
xip.order_by
xip.parent_hierarchy
xip.parent_ref
…
If an index on a metadata attribute is not available, its straightforward to create a new index using a custom search configuration.
You can now use these indexes to create your search query.
Simple Reports
Using the raw REST API you would first create a JSON document containing the search terms and POST it to the
/api/content/search
endpoint.
The JSON document syntax is described in the swagger documentation.
Again to simplify the process we will use the pyPreservica client which creates the JSON document for you.
To create a report using the basic “google” type search which searches across all the indexes we use the
simple_search_csv()
method.
You can include any query term to search on, the special % character matches on everything in the repository.
This function will search the Preservica repository for the term supplied in the query argument across all indexes and save the results into a UTF-8 CSV file which can be opened in MS Excel.
For example, the following script will create a CSV file containing everything in the repository.
from pyPreservica import *
search = ContentAPI()
search.simple_search_csv(query="%", csv_file="results.csv")
By default the spreadsheet columns correspond to the following indexes
- xip.reference The entity reference of the asset or folder
- xip.title The title of the asset or folder
- xip.description The description of the asset or folder
- xip.document_type The type of entity, e.g, “IO” for asset and “SO” for folder
- xip.parent_ref The entity reference of the parent folder
- xip.security_descriptor The security tag
Once opened in Excel, then you can use the standard tools for filtering and sorting the tabulated data.
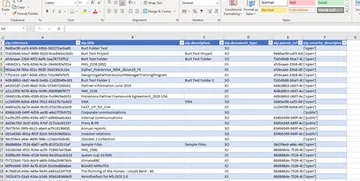
You can customise the CSV file and select your own spreadsheet columns by adding a list of indexes you would like to see in the output as the last argument of the function. For example you could search for the term “Oxford” across all the indexes and have the resulting CSV file include two Dublin core attributes as columns.
from pyPreservica import *
search = ContentAPI()
indexes = ['xip.reference', 'xip.title', 'oai_dc.identifier', 'oai_dc.subject']
search.simple_search_csv("Oxford", "oxford-results.csv", indexes)
Fielded Reports
This method described above works well as long as you want to query across all the available indexes, if you want to do more selective reporting such as filtering results based on specific index values then you need to use a different function search_index_filter_csv().
To filter the results of the query you need to pass a Python dictionary rather than a simple list, the dictionary elements contain the index names as above and also the index values.
For example, to only return Assets from the query we can filter on the xip.document_type index, assets are indexed using the term “IO” for intellectual objects and folders are indexed using “SO” for structural objects.
from pyPreservica import *
search = ContentAPI()
filters = {'xip.document_type': 'IO'}
search.search_index_filter_csv("Oxford", "oxford-results.csv", filters)
This returns a CSV document with a column for each filtered field.
If you want to include additional columns in the resulting CSV file but don’t want to filter on their values, then leave the filter value empty, e.g.
from pyPreservica import *
search = ContentAPI()
filters = {'xip.document_type': 'IO', 'xip.title': '', 'xip.description': ''}
search.search_index_filter_csv("Oxford", "oxford-results.csv", filters)
To return only Assets with an open security tag we could use:
from pyPreservica import *
search = ContentAPI()
filters = {'xip.document_type': 'IO', 'xip.security_descriptor': 'open' }
search.search_index_filter_csv("Oxford", "oxford-results.csv", filters)
This example queries for the term “Oxford” across all indexes and also filters for the term “University” within the full text index which has been extracted from the text within documents.
It returns only assets which have the security tag “open”
from pyPreservica import *
search = ContentAPI()
filters = {'xip.document_type': 'IO', 'xip.security_descriptor': 'open', 'xip.full_text': 'University’}
search.search_index_filter_csv("Oxford", "oxford-results.csv", filters)
If you want to limit your search to assets within a single folder, then you can use the parent reference filter, passing the reference of the folder of interest.
from pyPreservica import *
search = ContentAPI()
filters = {'xip.document_type': 'IO', 'xip.security_descriptor': 'open', 'xip.full_text': 'University’, 'xip.parent_ref': '123e4567-e89b-12d3-a456-426614174000'}
search.search_index_filter_csv("Oxford", "oxford-results.csv", filters)
If you want to search for objects within a folder hierarchy, i.e. recursively down the hierarchy then replace xip.parent_ref with the xip.parent_hierarchy index.
from pyPreservica import *
search = ContentAPI()
filters = {'xip.document_type': 'IO', 'xip.security_descriptor': 'open', 'xip.full_text': 'University’, 'xip.parent_hierarchy': '123e4567-e89b-12d3-a456-426614174000'}
search.search_index_filter_csv("Oxford", "oxford-results.csv", filters)
Providing Feedback
Searching across a large Preservica repository is quick, but returning large datasets back to the client can be slow. To avoid putting undue load on the server pyPreservica will request a single page of results at a time for each server request. This paging is handled automatically by the pyPreservica client.
If you are using the `simple_search_csv()` or `search_index_filter_csv()` functions which write directly to a CSV file then it can be difficult to monitor the report generation progress.
To allow monitoring of search result downloads, you can add a Python call back object to the search client. The call back class will be called for every page of search results returned to the client. The value passed to the call back contains the total number of search hits for the query and the current number of results processed. The allows the current report progress to be displayed and updated on the console as the script is running.
You can create your own call back functions or use the default provided by pyPreservica
from pyPreservica import *
search = ContentAPI()
search.search_callback(ReportProgressConsoleCallback())
filters = {'xip.document_type': 'IO', 'xip.security_descriptor': 'open', 'xip.full_text': 'University’, 'xip.parent_hierarchy': '123e4567-e89b-12d3-a456-426614174000'}
search.search_index_filter_csv("Oxford", "oxford-results.csv", filters)
This script will now display onto the console a message like:
Progress: |██████████---------------------------------------------| (10.18%)
as the search progresses.
Counting Results
Sometimes you don’t need the full search results, only the number of elements in the search results, i.e the search hit count.
The number of hits can be evaluated using the `search_index_filter_hits()` function
from pyPreservica import *
search = ContentAPI()
filters = {'xip.document_type': 'IO', 'xip.security_descriptor': 'open', 'xip.full_text': 'University’, 'xip.parent_hierarchy': '123e4567-e89b-12d3-a456-426614174000'}
hits = search.search_index_filter_hits("Oxford", "oxford-results.csv", filters)
Having the hit count can be useful for creating frequency histograms etc, the following is a simple python script which uses the pygal charting library to generate a histogram of the number of assets within a Preservica repository by security tag.
The script first queries the API for a list of security tags used by the system and for each security tag, it uses the search API to fetch the number of assets which that tag.
import pygal
from pygal.style import BlueStyle
from pyPreservica import *
client = AdminAPI()
search = ContentAPI()
security_tags = client.security_tags()
results = {}
for tag in security_tags:
filters = {"xip.security_descriptor": tag, "xip.document_type": "IO"}
hits = search.search_index_filter_hits(query="%", filter_values=filters)
results[tag] = hits
bar_chart = pygal.HorizontalBar(show_legend=False)
bar_chart.title = "Security Tag Frequency"
bar_chart.style = BlueStyle
bar_chart.x_title = "Number of Assets"
bar_chart.x_labels = results.keys()
bar_chart.add("Security Tag", results)
bar_chart.render_to_file("chart.svg")

The pyPreservica documentation contains some more common examples of reports to try.
More updates from Preservica
Using OPEX and PAX for Ingesting Content
Preservica has developed the concept of an OPEX (Open Preservation Exchange) package, a collection of files and folders with optional metadata, as a way to organise content into an easy to understand format for transfer into or out of a digital preservation system. Although we have created it, we hope suppliers of digital content to be preserved, and other digital preservation systems, will use it due to its simplicity.

Richard Smith
January 28th, 2021
Using the PAR API to create Custom Migrations
Since the release of v6, Preservation Actions within Preservica have been defined and controlled using a PAR (Preservation Action Registries) data model. To facilitate this, Preservica’s registry also exposes a PAR API to allow a full range of CRUD operations on this data. This API also makes it possible to write new migration actions using Preservica’s existing toolset, for example, to introduce re-scaling to your image/video migrations, or to get different output formats altogether. In this article, we will introduce the key concepts in this data model, explain how Preservica uses and interpret them, and introduce the API calls required to create your own custom actions. We will do this by a worked example, using ImageMagick to create a custom “re-size migration” for images.

Jack O'Sullivan
August 11th, 2020
Using Python with the Preservica Entity APIs (Part 3)
In this article we will be looking at API calls which create and update entities within the repository, some calls to add and update descriptive metadata and we will also look at the use of external identifiers which are useful if you want to synchronise external metadata sources to Preservica.
James Carr
June 11th, 2020
Using Python with the Preservica Entity APIs (Part 2)
In my previous article on using the Preservica Entity API with Python we looked at creating the authentication token used by all the web service calls and then showed how we could use the token to request basic information about the intellectual assets held in the Preservica repository.
James Carr
May 27th, 2020
 Preservica on Github
Preservica on Github
Open API library and latest developments on GitHub
Visit the Preservica GitHub page for our extensive API library, sample code, our latest open developments and more.
 Preservica.com
Preservica.com
Protecting the world’s digital memory
The world's cultural, economic, social and political memory is at risk. Preservica's mission is to protect it.