Using Python with the Preservica Entity APIs (Part 3)

James Carr
June 11th, 2020
In this article we will be looking at API calls which create and update entities within the repository, some calls to add and update descriptive metadata and we will also look at the use of external identifiers which are useful if you want to synchronise external metadata sources to Preservica.
The first API call we will look at is creating Preservica folders programmatically rather than through the Explorer interface.
Folders/Collections are created by POSTing an XML document to the /structural-objects endpoint. POST is the Restful verb we use when we would like to create a new entity on the server.
Looking at the documentation for this endpoint we see that we need to create an XML document which looks like the following:

The XML fragment contains the basic metadata fields needed to create and populate a new folder object along with its unique identifier.
We can create the required XML document by using the same python XML ElementTree library we have been using for parsing XML documents in the previous examples. We create the XML root element remembering to add the correct namespace and then add the required sub elements.
The python function we are going to create takes 4 parameters 3 of which (title, description and security tag) are mandatory and the last, Parent is an optional parameter not shown in the documentation. If we don’t specify the parent identifier, we will create a top-level folder at the root of the repository hierarchy.
We can create a unique reference for the new folder by calling the python UUID library function uuid4() which creates a type 4 UUID which is guaranteed to be unique.
The XML document is serialised to a UTF-8 string and passed as the payload to the POST request. As we are now sending XML data in the request body, we have added an additional HTTP header with the content type attribute to let the server know we are sending XML.
The function will also parse the returned XML response from the server, create a new python folder object and pass that back to the caller.
def create_folder(self, title, description, security_tag, parent=None):
headers = {'Preservica-Access-Token': self.token, 'Content-Type': 'application/xml;charset=UTF-8'}
structuralobject = xml.etree.ElementTree.Element('StructuralObject', {"xmlns": "http://preservica.com/XIP/v6.0"})
xml.etree.ElementTree.SubElement(structuralobject, "Ref").text = str(uuid.uuid4())
xml.etree.ElementTree.SubElement(structuralobject, "Title").text = title
xml.etree.ElementTree.SubElement(structuralobject, "Description").text = description
xml.etree.ElementTree.SubElement(structuralobject, "SecurityTag").text = security_tag
if parent is not None:
xml.etree.ElementTree.SubElement(structuralobject, "Parent").text = parent
xml_request = xml.etree.ElementTree.tostring(structuralobject, encoding='utf-8')
request = requests.post(f'https://{self.server}/api/entity/structural-objects', data=xml_request, headers=headers)
if request.status_code == 200:
xml_response = str(request.content.decode('UTF-8'))
entity = __entity__(xml_response)
f = self.Folder(entity['reference'], entity['title'], entity['description'], entity['security_tag'],
entity['parent'],
entity['metadata'])
return f
elif request.status_code == 401:
self.token = self.__token__()
return self.create_folder(title, description, security_tag, parent=parent)
else:
print(f"create_folder failed with error code: {request.status_code}")
print(request.request.url)
raise SystemExit
As in the previous examples a returned status code of 401 indicates the authentication token has expired.
The following is an example of how we might use the function to create folders based on information in a spreadsheet.
If we export the spreadsheet as a CSV file containing folder names, descriptions and security tags such as:
folder1, description1, open
folder2, description2, open
folder3, description3, open
Then the following Python code will create a new folder for every row in the CSV file.
from EntityAPI.entityAPI import EntityAPI
import csv
entity = EntityAPI(username="test@test.com", password="1234ASDFG", tenant="PREVIEW", server="preview.preservica.com")
with open('folders.csv', newline='') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
entity.create_folder(row[0], row[1], row[2])
The result of running this script is the following folders are created in Preservica.
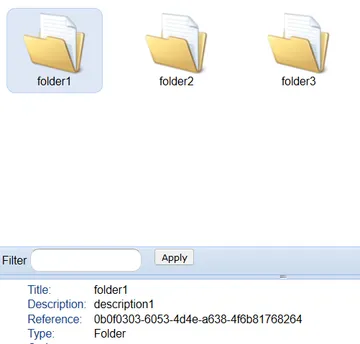
The next activity we may wish to carry out is to update the title or description for a folder or asset. The relevant call here is the PUT method for asset and folder, these calls work in the same way and only differ by the endpoint URLs. This means we can probably write a single python function to cover updating both types of entity.
Something to note here is that this endpoint only allows changes to the Title and Description attributes. If we want to change the parent of an entity which is equivalent to a move within the repository or change the security tag we need to use a different endpoint.
The python code for updating entities is nearly identical to the previous function for creating new folders. The only changes we are making is to support both assets and folders and a change to the request verb from POST to PUT.
The first part of the function just tests which type of entity is passed in and sets the endpoint and XML root element appropriately.
def save(self, entity):
headers = {'Preservica-Access-Token': self.token, 'Content-Type': 'application/xml;charset=UTF-8'}
if isinstance(entity, self.Asset):
end_point = "/information-objects"
xml_object = xml.etree.ElementTree.Element('InformationObject', {"xmlns": "http://preservica.com/XIP/v6.0"})
elif isinstance(entity, self.Folder):
end_point = "/structural-objects"
xml_object = xml.etree.ElementTree.Element('StructuralObject', {"xmlns": "http://preservica.com/XIP/v6.0"})
else:
return
xml.etree.ElementTree.SubElement(xml_object, "Ref").text = entity.reference
xml.etree.ElementTree.SubElement(xml_object, "Title").text = entity.title
xml.etree.ElementTree.SubElement(xml_object, "Description").text = entity.description
xml.etree.ElementTree.SubElement(xml_object, "SecurityTag").text = entity.security_tag
if entity.parent is not None:
xml.etree.ElementTree.SubElement(xml_object, "Parent").text = entity.parent
xml_request = xml.etree.ElementTree.tostring(xml_object, encoding='utf-8')
request = requests.put(f'https://{self.server}/api/entity{end_point}/{entity.reference}', data=xml_request, headers=headers)
if request.status_code == 200:
xml_response = str(request.content.decode('UTF-8'))
response = __entity__(xml_response)
if isinstance(entity, self.Asset):
return self.Asset(response['reference'], response['title'], response['description'],
response['security_tag'],
response['parent'], response['metadata'])
else:
return self.Folder(response['reference'], response['title'], response['description'],
response['security_tag'],
response['parent'], response['metadata'])
elif request.status_code == 401:
self.token = self.__token__()
return self.save(entity)
else:
print(f"save failed with error code: {request.status_code}")
print(request.request.url)
raise SystemExit
To use this function to update entities we simply call the save method on either an asset or folder.
folder = entity.folder("0b0f0303-6053-4d4e-a638-4f6b81768264")
folder.title = "New Folder Title"
folder.description = "New Folder Description"
folder = entity.save(folder)
asset = entity.asset("9bad5acf-e7ce-458a-927d-2d1e7f15974d")
asset.title = "New Asset Title"
asset.description = "New Asset Description"
asset = entity.save(asset)
One common use case we should also cover is attaching custom descriptive metadata to assets or folders. Preservica is designed to allow any type of descriptive metadata to be attached to entities. Metadata need only be well formed XML with a valid URI namespace.
To add new descriptive metadata to either an asset or folder we need to create an XML document containing our well-formed descriptive XML document and post it to either the /information-objects or /structural-objects endpoints. We can POST the same XML document to either endpoint, so as before we can write a single python function to cover both use cases.
Looking at the documentation, we need to create an XML document which wraps our own metadata fragment. Our custom metadata goes inside the <Content> element. We must also make sure that the namespace of our custom fragment is also set on the schemaURI attribute of the root element and they match exactly.

To make the call to add metadata more usable we are going to add some flexibility into the function to allow callers to specify their metadata in two different ways. We are going to allow the descriptive metadata to be defined as a simple string representation of an XML document and, as an existing file containing an XML data.
The complete python function is show below.
def add_metadata(self, entity, namespace, data):
headers = {'Preservica-Access-Token': self.token, 'Content-Type': 'application/xml;charset=UTF-8'}
xml_object = xml.etree.ElementTree.Element('MetadataContainer',
{"schemaUri": namespace, "xmlns": "http://preservica.com/XIP/v6.0"})
xml.etree.ElementTree.SubElement(xml_object, "Entity").text = entity.reference
content = xml.etree.ElementTree.SubElement(xml_object, "Content")
if isinstance(data, str):
ob = xml.etree.ElementTree.fromstring(data)
content.append(ob)
if isinstance(data, IOBase):
tree = xml.etree.ElementTree.parse(data)
content.append(tree.getroot())
xml_request = xml.etree.ElementTree.tostring(xml_object, encoding='UTF-8', xml_declaration=True)
if isinstance(entity, self.Asset):
end_point = f"/information-objects/{entity.reference}/metadata"
else:
end_point = f"/structural-objects/{entity.reference}/metadata"
request = requests.post(f'https://{self.server}/api/entity{end_point}', data=xml_request, headers=headers)
if request.status_code == 200:
if isinstance(entity, self.Asset):
return self.asset(entity.reference)
else:
return self.folder(entity.reference)
elif request.status_code == 401:
self.token = self.__token__()
return self.add_metadata(entity, namespace, data)
else:
print(f"add_metadata failed with error code: {request.status_code}")
print(request.request.url)
raise SystemExit
We have added the following two options allow users to determine how the data has been passed to the function. IOBase is used to select the option where data is read from a file.
if isinstance(data, str):
ob = xml.etree.ElementTree.fromstring(data)
content.append(ob)
if isinstance(data, IOBase):
tree = xml.etree.ElementTree.parse(data)
content.append(tree.getroot())
The function can then be used in the following ways:
# add descriptive metadata to a folder from a string
xml_string = "<person:Person xmlns:person='https://www.person.com/person'>" \
"<person:Name></person:Name>" \
"<person:Phone>1234</person:Phone>" \
"<person:Email>test@test.com</person:Email>" \
"<person:Address>Abingdon</person:Address>" \
"</person:Person>"
folder = entity.add_metadata(folder, "https://www.person.com/person", xml_string)
# add descriptive metadata to an asset from a file
with open("C:\\DublinCore.xml", 'r', encoding="UTF-8") as md:
asset = entity.add_metadata(asset, "http://purl.org/dc/elements/1.1/", md)
We can add a method to update existing metadata in the same way, this time we loop over all the metadata fragments until we find one with a matching namespace.
def update_metadata(self, entity, namespace, data):
headers = {'Preservica-Access-Token': self.token, 'Content-Type': 'application/xml;charset=UTF-8'}
for url in entity.metadata:
if namespace == entity.metadata[url]:
mref = url[url.rfind(f"{entity.reference}/metadata/") + len(f"{entity.reference}/metadata/"):]
xml_object = xml.etree.ElementTree.Element('MetadataContainer', {"schemaUri": namespace,
"xmlns": "http://preservica.com/XIP/v6.0"})
xml.etree.ElementTree.SubElement(xml_object, "Ref").text = mref
xml.etree.ElementTree.SubElement(xml_object, "Entity").text = entity.reference
content = xml.etree.ElementTree.SubElement(xml_object, "Content")
if isinstance(data, str):
ob = xml.etree.ElementTree.fromstring(data)
content.append(ob)
if isinstance(data, IOBase):
tree = xml.etree.ElementTree.parse(data)
content.append(tree.getroot())
xml_request = xml.etree.ElementTree.tostring(xml_object, encoding='UTF-8', xml_declaration=True)
request = requests.put(f'{url}', data=xml_request, headers=headers)
if request.status_code == 200:
if isinstance(entity, self.Asset):
return self.asset(entity.reference)
else:
return self.folder(entity.reference)
elif request.status_code == 401:
self.token = self.__token__()
return self.update_metadata(entity, namespace, data)
else:
print(f"update_metadata failed with error code: {request.status_code}")
print(request.request.url)
raise SystemExit
Now we have functions to add and update metadata we can use these functions to carry out some realistic use cases.
The following example shows how we can use our new API library to add some descriptive metadata to an entity (a folder in this example) and then update the metadata to include new attributes.
The following python script we looked at above will add the descriptive fragment holding metadata about a person.
from EntityAPI.entityAPI import EntityAPI
entity = EntityAPI(username="james@preservica.com", password="123456", tenant="PREVIEW", server="preview.preservica.com")
folder = entity.folder("723f6f27-c894-4ce0-8e58-4c15a526330e")
xml = "<person:Person xmlns:person='https://www.person.com/person'>" \
"<person:Name>James Carr</person:Name>" \
"<person:Phone>01234 100 100</person:Phone>" \
"<person:Email>test@test.com</person:Email>" \
"<person:Address>Abingdon, UK</person:Address>" \
"</person:Person>"
folder = entity.add_metadata(folder, "https://www.person.com/person", xml)
Running the script against our Preservica system gives the following in Explorer.

We now would like to update the metadata to include a new attribute such as a user’s postcode/zipcode.
This python script calls three methods on our API library the first request is to get the folder by its identifier, it then loops through all the descriptive metadata fragments until it finds one with the matching namespace of the document we would like to update. It then fetches the metadata from Preservica as a string and uses the python ElementTree library to append a new element and then it calls the update method to save the new metadata back to Preservica.
from EntityAPI.entityAPI import EntityAPI
from xml.etree import ElementTree
entity = EntityAPI(username="james@preservica.com", password="123456", tenant="PREVIEW", server="preview.preservica.com")
folder = entity.folder("723f6f27-c894-4ce0-8e58-4c15a526330e") # call into the API
for url, schema in folder.metadata.items():
if schema == "https://www.person.com/person":
xml_string = entity.metadata(url) # call into the API
xml_document = ElementTree.fromstring(xml_string)
postcode = ElementTree.Element('{https://www.person.com/person}Postcode')
postcode.text = "OX14 3YS"
xml_document.append(postcode)
xml_string = ElementTree.tostring(xml_document, encoding='UTF-8', xml_declaration=True).decode("utf-8")
entity.update_metadata(folder, schema, xml_string) # call into the API
The end result of this script is the following updated metadata in Preservica.

We now have a library which can fetch entities back from Preservica, check to see if they have any descriptive metadata, add any missing metadata and also update entities with new metadata. This is enough functionality to start to provide simple metadata synchronisation with external systems such as metadata catalogues and other types of repositories.
The one limitation we would run into when building a python script to carry out metadata synchronisation is fetching the entities such as assets and folders back from Preservica. Currently our library only allows the retrieval of entities by the internal Preservica identifier which is normally a UUID. If this Preservica identifier is not held in the external system, then matching entities between systems will be a problem.
What we would like to do is find and update entities in Preservica using the identifier held in the external 3rd party system. Fortunately, Preservica has a mechanism for doing exactly this using its external identifiers.
Each entity (folder or asset) in Preservica can hold a set of 3rd party identifiers, each identifier has a type such as “ISBN”, “DOI”, “ARK” etc and an associated value. Entities can contain multiple identifiers and users are free to choose any label for the identifier type.
Once the identifier has been set on the entity, we can use the API to request the asset back only using this identifier and therefore decouple the Preservica API from the internal Preservica only identifiers.
The external identifiers can be set directly on the asset during submission using a 3rd party tool such as the asset-creator or we can add them through the user interface manually or via the API, the function below takes the entity we wish to update and adds the identifier type and its value.
def add_identifier(self, entity, identifier_type, identifier_value):
headers = {'Preservica-Access-Token': self.token, 'Content-Type': 'application/xml;charset=UTF-8'}
xml_object = xml.etree.ElementTree.Element('Identifier', {"xmlns": "http://preservica.com/XIP/v6.0"})
xml.etree.ElementTree.SubElement(xml_object, "Type").text = identifier_type
xml.etree.ElementTree.SubElement(xml_object, "Value").text = identifier_value
xml.etree.ElementTree.SubElement(xml_object, "Entity").text = entity.reference
if isinstance(entity, self.Asset):
end_point = f"/information-objects/{entity.reference}/identifiers"
else:
end_point = f"/structural-objects/{entity.reference}/identifiers"
xml_request = xml.etree.ElementTree.tostring(xml_object, encoding='UTF-8', xml_declaration=True)
request = requests.post(f'https://{self.server}/api/entity{end_point}', data=xml_request, headers=headers)
if request.status_code == 200:
xml_string = str(request.content.decode("UTF-8"))
identifier_response = xml.etree.ElementTree.fromstring(xml_string)
aip_id = identifier_response.find('.//{http://preservica.com/XIP/v6.0}ApiId')
if hasattr(aip_id, 'text'):
return aip_id.text
else:
return None
elif request.status_code == 401:
self.token = self.__token__()
return self.add_identifier(entity, identifier_type, identifier_value)
else:
print(f"add_identifier failed with error code: {request.status_code}")
print(request.request.url)
raise SystemExit
Using the function above we can add external identifiers using the following python code.
asset = entity.asset("9bad5acf-e7ce-458a-927d-2d1e7f15974d")
entity.add_identifier(asset, "ISBN", "978-3-16-148410-0")
entity.add_identifier(asset, "DOI", "https://doi.org/10.1109/5.771073")
entity.add_identifier(asset, "URN", "urn:isan:0000-0000-2CEA-0000-1-0000-0000-Y")
Once we have external identifiers attached to the assets within the system its straightforward to query for assets based on the identifier values. One thing to be aware of is that external identifiers are not guaranteed to be unique like the internal identifiers so our API call to fetch entities back returns a set of entities which match the identifier type and value.
for e in entity.identifier("ISBN", "978-3-16-148410-0"):
print(e.type, e.reference, e.title)
The python code for the identifier call looks like the following.
def identifier(self, identifier_type, identifier_value):
payload = {'type': identifier_type, 'value': identifier_value}
request = requests.get(f'https://{self.server}/api/entity/entities/by-identifier', params=payload, headers=headers)
if request.status_code == 200:
xml_response = str(request.content.decode('UTF-8'))
entity_response = xml.etree.ElementTree.fromstring(xml_response)
entity_list = entity_response.findall('.//{http://preservica.com/EntityAPI/v6.0}Entity')
result = set()
for entity in entity_list:
if entity.attrib['type'] == 'SO':
f = self.Folder(entity.attrib['ref'], entity.attrib['title'], None, None, None, None)
result.add(f)
else:
a = self.Asset(entity.attrib['ref'], entity.attrib['title'], None, None, None, None)
result.add(a)
return result
elif request.status_code == 401:
self.token = self.__token__()
return self.identifier(identifier_type, identifier_value)
else:
print(f"identifier failed with error code: {request.status_code}")
print(request.request.url)
raise SystemExit
In summary we now have an API library with the following calls:
- asset() Fetches the main attributes for an asset by its reference.
- folder() Fetches the main attributes for a folder by its reference.
- metadata() Return the descriptive metadata attached to an entity.
- save() Updates the title and description of an asset or folder.
- create_folder() Creates a new structural object in the repository.
- children() Returns a list of child entities from a folder.
- identifier() Returns an asset or folder based on an external identifier.
- add_identifier() Adds a new external identifier to an entity.
- add_metadata() Add new descriptive metadata to an entity.
- update_metadata() Update the descriptive metadata attached to an entity.
This should provide the basic building blocks to allow 3rd party metadata synchronisation between Preservica and external metadata repositories and catalogues.
The full source code for the python module and examples shown here is available at Github.
More updates from Preservica
Custom Reporting via the Preservica Content API
Preservica provides a REST API to allow users to query the underlying search engine. In this article we will show how CSV documents can be returned by the API.
James Carr
November 29th, 2021
Using OPEX and PAX for Ingesting Content
Preservica has developed the concept of an OPEX (Open Preservation Exchange) package, a collection of files and folders with optional metadata, as a way to organise content into an easy to understand format for transfer into or out of a digital preservation system. Although we have created it, we hope suppliers of digital content to be preserved, and other digital preservation systems, will use it due to its simplicity.

Richard Smith
January 28th, 2021
Using the PAR API to create Custom Migrations
Since the release of v6, Preservation Actions within Preservica have been defined and controlled using a PAR (Preservation Action Registries) data model. To facilitate this, Preservica’s registry also exposes a PAR API to allow a full range of CRUD operations on this data. This API also makes it possible to write new migration actions using Preservica’s existing toolset, for example, to introduce re-scaling to your image/video migrations, or to get different output formats altogether. In this article, we will introduce the key concepts in this data model, explain how Preservica uses and interpret them, and introduce the API calls required to create your own custom actions. We will do this by a worked example, using ImageMagick to create a custom “re-size migration” for images.

Jack O'Sullivan
August 11th, 2020
Using Python with the Preservica Entity APIs (Part 2)
In my previous article on using the Preservica Entity API with Python we looked at creating the authentication token used by all the web service calls and then showed how we could use the token to request basic information about the intellectual assets held in the Preservica repository.
James Carr
May 27th, 2020
 Preservica on Github
Preservica on Github
Open API library and latest developments on GitHub
Visit the Preservica GitHub page for our extensive API library, sample code, our latest open developments and more.
 Preservica.com
Preservica.com
Protecting the world’s digital memory
The world's cultural, economic, social and political memory is at risk. Preservica's mission is to protect it.