Using Python with the Preservica Entity APIs (Part 1)

James Carr
May 13th, 2020
The Preservica Entity API provides a set of Restful web services to allow users to interact with the Preservica repository. The services allow both the reading and writing of metadata attached to both digital assets and their parent aggregations or collections. The API also allows read access to the digital content within the assets.
In part 1 of this series of blog posts I will show you how to create authenticated calls to the web service in Python and requesting basic information on Preservica assets.
Data Model
They key to working with the entity API is that the services follow the core data model closely.
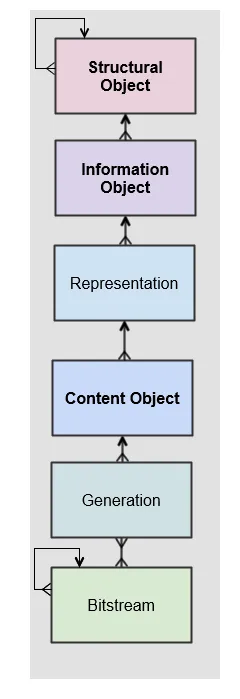
The data model represents a hierarchy of entities, starting with the structural objects which are used to represent aggregations of digital assets. Structural objects define the organisation of the data. In a library context they may be referred to as collections, in an archival context they may be Fonds, Sub-Fonds, Series etc and in a records management context they could be simply a hierarchy of folders or directories.
These structural objects may contain other structural objects in the same way as a computer filesystem may contain folders within folders.
Within the structural objects comes the information objects. These objects which are sometimes referred to as the digital assets are what PREMIS defines as an Intellectual Entity. Information objects are considered a single intellectual unit for purposes of management and description: for example, a book, document, map, photograph or database etc.
Representations are used to define how the information object are composed in terms of technology and structure. For example, a book may be represented as a single multiple page PDF, a single eBook file or a set of single page image files.
Representations are usually associated with a use case such as access or long-term preservation. All Information objects have a least one representation defined by default. Multiple representations can be either created outside of Preservica through a process such as digitisation or within Preservica through preservation processes such a normalisation.
Content Objects represent the components of the asset. Simple assets such as digital images may only contain a single content object whereas more complex assets such as books or 3d models may contain multiple content objects. In most cases content objects will map directly to digital files or bitstreams.
Generations represent changes to content objects over time, as formats become obsolete new generations may need to be created to make the information accessible.
Bitstreams represent the actual computer files as ingested into Preservica, i.e. the TIFF photograph or the PDF document.
Python
Python is an interpreted computer language which makes working with web services very easy. One of the advantages of python is the wide range of standard libraries included with the language which make working with the technologies used by web services such as HTTP, XML and JSON so simple.
The following examples will all use the python 3 libraries requests and elementTree
- The requests library is a simple web library for python which allows you to make HTTP/1.1 requests easily.
- elementTree is a library for parsing and creating XML documents.
Authentication
All web service requests to the entity API are authenticated. To request information back from the API you will need a valid Preservica username and password to generate an access token. The access token is then used with the API calls to validate the request. Using time limited authentication tokens is the preferred method of securing web services.
The access provided by the API will respect the roles and permission your account has been granted. This means you have the same level of access through the API as your username/password provides through the main Preservica user interface.
All requests through the API require authentication even those requesting information which has been made public through Universal Access.
To use the requests and ElementTree libraries add the following import statements to your python scripts:
import requests
from xml.etree import ElementTree
The following is an example python function to create a new access token. Note that the request requires your Preservica tenancy name in addition to your username and password and server is the URL to your Preservica instance, for example eu.preservica.com
The actual HTTPS request returns a json string containing the access token. The json string can be converted into a python dict container using the requests library and the token returned by requesting the value of the ‘token’ key.
{
"success" : true,
"token" : "664c455f-59f2-4c83-9d7a-ddfe5e4b363d",
"refresh-token" : "3bb58740-db8e-4332-bcff-7a7435f5686e",
"validFor" : 15,
"user" : "John Doe"
}
The following is a simple python function which returns a valid authentication token when passed user details. We check for a successful web service call by comparing the status of the response to the standard HTTP 200 OK.
def new_token(username, password, tenant, server):
response = requests.post(f'https://{server}/api/accesstoken/login?username={username}&password={password}&tenant={tenant}')
if response.status_code == 200:
return response.json()['token']
else:
print(f"new_token failed with error code: { response.status_code}")
print(response.request.url)
raise SystemExit
Tokens returned from this API call are valid for 15mins.
Requesting Information
Once you have a valid access token you can start to make simple requests through the API to your Preservica repository.
For example we can retrieve information about assets using the unique reference id.
This call will return an XML document with the main details such as title, description etc for an asset.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<EntityResponse xmlns="http://preservica.com/EntityAPI/v6.0" xmlns:xip="http://preservica.com/XIP/v6.0">
<xip:InformationObject>
<xip:Ref>a9e1cae8-ea06-4157-8dd4-82d0525b031c</xip:Ref>
<xip:Title>filey_brigg</xip:Title>
<xip:Description>An image of Filey Brigg</xip:Description>
<xip:SecurityTag>open</xip:SecurityTag>
<xip:Parent>866d4c6e-ee51-467a-b7a3-e4b65709cf95</xip:Parent>
</xip:InformationObject>
<AdditionalInformation>
<Self>https://us.preservica.com/api/entity/information-objects/a9e1cae8-ea06-4157-8dd4-82d0525b031c</Self>
<Links>https://us.preservica.com/api/entity/information-objects/a9e1cae8-ea06-4157-8dd4-82d0525b031c/links</Links>
<Identifiers>https://us.preservica.com/api/entity/information-objects/a9e1cae8-ea06-4157-8dd4-82d0525b031c/identifiers</Identifiers>
<Representations>https://us.preservica.com/api/entity/information-objects/a9e1cae8-ea06-4157-8dd4-82d0525b031c/representations</Representations>
<Metadata>
<Fragment schema="http://preservica.com/schema/sample/v1.0">https://us.preservica.com/api/entity/information-objects/a9e1cae8-ea06-4157-8dd4-82d0525b031c/metadata/dda13399-a6c1-420e-8d47-458062c43209</Fragment>
</Metadata>
</AdditionalInformation>
</EntityResponse>
Note that the returned XML contains two different namespaces, one for the entity response wrapper and one for the asset attributes.
The following python function returns the asset title and description and takes a valid authentication token and Preservica asset identifier reference.
def get_asset_title(server, token, ref):
headers = {'Preservica-Access-Token': token}
io_request = requests.get(f'https://{server}/api/entity/information-objects/{ref}', headers=headers)
if io_request.status_code == 200:
xml_response = str(io_request.content.decode('UTF-8'))
entity_response = ElementTree.fromstring(xml_response)
title = entity_response.find('.//{http://preservica.com/XIP/v6.0}Title')
description = entity_response.find('.//{http://preservica.com/XIP/v6.0}Description')
return title.text, description.text
else:
print(f"get_asset failed with error code: {io_request.status_code}")
print(io_request.request.url)
raise SystemExit
The function works by call the request library on the information object URL. If the request is successful, i.e. the token and reference id are both valid, then the status code return is again HTTP 200 OK.
The function decodes the response body into a string using UTF-8 encoding and creates an in-memory XML document using the element tree library. The asset title and description are then pulled from the XML document using namespace aware XPATH expressions.
The title and description are then both returned as a python tuple to the calling program.
If we put the functions above into a new python module called “preservica.py” we have the start of our python Preservica API module:
from xml.etree import ElementTree
import requests
def new_token(username, password, tenant, server):
response = requests.post(
f'https://{server}/api/accesstoken/login?username={username}&password={password}&tenant={tenant}')
if response.status_code == 200:
return response.json()['token']
else:
print(f"new_token failed with error code: {response.status_code}")
print(response.request.url)
raise SystemExit
def get_asset_title(server, token, ref):
headers = {'Preservica-Access-Token': token}
io_request = requests.get(f'https://{server}/api/entity/information-objects/{ref}', headers=headers)
if io_request.status_code == 200:
xml_response = str(io_request.content.decode('UTF-8'))
entity_response = ElementTree.fromstring(xml_response)
title = entity_response.find('.//{http://preservica.com/XIP/v6.0}Title')
description = entity_response.find('.//{http://preservica.com/XIP/v6.0}Description')
return title.text, description.text
else:
print(f"get_asset failed with error code: {io_request.status_code}")
print(io_request.request.url)
raise SystemExit
if __name__ == "__main__":
username = "test@test.com"
password = "xxx"
tenant = "TEN"
server = "us.preservica.com"
accessToken = new_token(username, password, tenant, server)
asset = get_asset_title(server, accessToken, "6a596701-75ae-45b7-933d-355787e25a28")
print("Title: " + asset[0])
print("Description: " + asset[1])
A copy of the python module has been upload to the github.com site.
In the next part of this Preservica API series we will be looking at two more common use cases for the APIs, querying Preservica for descriptive metadata attached to assets and returning lists of entities belonging to collections.
More updates from Preservica
Custom Reporting via the Preservica Content API
Preservica provides a REST API to allow users to query the underlying search engine. In this article we will show how CSV documents can be returned by the API.
James Carr
November 29th, 2021
Using OPEX and PAX for Ingesting Content
Preservica has developed the concept of an OPEX (Open Preservation Exchange) package, a collection of files and folders with optional metadata, as a way to organise content into an easy to understand format for transfer into or out of a digital preservation system. Although we have created it, we hope suppliers of digital content to be preserved, and other digital preservation systems, will use it due to its simplicity.

Richard Smith
January 28th, 2021
Using the PAR API to create Custom Migrations
Since the release of v6, Preservation Actions within Preservica have been defined and controlled using a PAR (Preservation Action Registries) data model. To facilitate this, Preservica’s registry also exposes a PAR API to allow a full range of CRUD operations on this data. This API also makes it possible to write new migration actions using Preservica’s existing toolset, for example, to introduce re-scaling to your image/video migrations, or to get different output formats altogether. In this article, we will introduce the key concepts in this data model, explain how Preservica uses and interpret them, and introduce the API calls required to create your own custom actions. We will do this by a worked example, using ImageMagick to create a custom “re-size migration” for images.

Jack O'Sullivan
August 11th, 2020
Using Python with the Preservica Entity APIs (Part 3)
In this article we will be looking at API calls which create and update entities within the repository, some calls to add and update descriptive metadata and we will also look at the use of external identifiers which are useful if you want to synchronise external metadata sources to Preservica.
James Carr
June 11th, 2020
 Preservica on Github
Preservica on Github
Open API library and latest developments on GitHub
Visit the Preservica GitHub page for our extensive API library, sample code, our latest open developments and more.
 Preservica.com
Preservica.com
Protecting the world’s digital memory
The world's cultural, economic, social and political memory is at risk. Preservica's mission is to protect it.